在网络通信中,很多情况下:比如说QQ聊天,通讯双方直接传递的都是字符信息。但是字符信息并不能够直接通过网络传输,这些字符集必须先转换成一个字节序列后才能够在网络中传输,于是这里就产生了编码和解码的概念:
- 将字符序列转换为字节序列的过程称之为:编码
- 将编码的字节序列转换为字符序列的过程称之为:解码
例如:对于Unicode字符来说,编码是指将一组Unicode字符转换为一个字节序列的过程,解码就是讲一个编码字节序列转换为一组Unicode字符。
目录索引:
1.字符编码基础知识 1.1 ASCII字符集 1.2 非ASCII字符集 1.3 Unicode字符集 1.4 UTF(通用转换格式)的出现 2.C#中不同编码和Unicode之间的转换 2.1 获取系统所有编码 2.2 获取指定编码信息 2.3 不同编码间的转换 3.C#编码和解码
字符编码基础知识
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。常见的编码方式主要有一下三种:
1.1 ASCII字符集
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以勉强显示其他西欧语言。它是现今最通用的单字节编码系统(但是有被Unicode追上的迹象),并等同于国际标准ISO/IEC 646。
1.2 非ASCII字符集
由于ASCII字符集是针对英语设计的,当处理汉字等其他非拉丁语系的字符时,这种编码就不能适用了(因为适用128个字符表示英文是完全足够的,但是用了表示中文就远远不够了)。为了解决这个问题,不同的国加和地区制定了自己编码标准。中国一般适用国标码,常用的有GB2312-1980编码和GB183030-2000编码,其中GB183030-2000编码汉字更多,是中国计算机系统必须遵循的基础性标准之一。
1.3 Unicode字符集
由于每个国家、语系都拥有独立的编码方式,同一个二进制数字可以被解释成不同的字符,因此要想打开一个文本文件,就必须知道它的编码方式,否则就可能出现乱码。为了使用国际信息交流更加方便,非营利机构统一码联盟制定和标准化了Unicode字符集。使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示216(即65536)个字符。基本满足各种语言的使用。实际上当前版本的统一码并未完全使用这16位编码,而是保留了大量空间以作为特殊使用或将来扩展。
1.4 UTF(通用转换格式)的出现
Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的(例如:在C#中字符默认都是Unicode码,即一个英文字符占两个字节,一个汉字也是两个字节,这对于能适应ASCII字符集来表示的字符来说比较显得浪费。),对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称UTF)。目前流行和UFT格式包括UTF-8、UTF16和UTF-32。
其中,UTF-8编码是互联网上使用最广泛的一种UTF格式,这是一种变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0)。而遇到与其他Unicode字符混合的情况,将按一定算法转换,每个字符使用1-3个字节编码,并利用首位为0或1进行识别。这样对以7位ASCII字符为主的西文文档就大大节省了编码长度。UTF-8是与字节顺序无关的,它的字节顺序在所有系统中都是一样的,因此这种编码可以使排序变得很容易。
2.C#中不同编码和Unicode之间的转换
在C#语言中对于不同编码和Unicode之间的转换使用位于System.Text命名空间中的Encoding类。通过这个类我们可以为不同的字符集直接进行转换以及各个字符集的相关信息。
2.1 获取系统所有编码信息
我们通过调用Encoding类的GetEncoding()方法获取包含所有编码的数组,数组元素为EncodingInfo类,通过数组元素我们可以获得各种类型编码的信息。例如我们可以通过下面的代码获取主机上所有编码的信息:
//获取系统所有编码名称及其描述信息 EncodingInfo[] allEncoding = Encoding.GetEncodings(); foreach (EncodingInfo encoding in allEncoding) { Console.WriteLine("编码标识符:{0,-10}编码名称:{1,-12}编码说明:{2}", encoding.CodePage, encoding.Name, encoding.DisplayName); } Console.ReadLine(); 运行如下:

2.2 获取指定的编码信息
Encoding 类提供了常用的字符集编码可以直接通过调用属性获取:UTF-8,ASCII 等属性,也可以通过调用GetEncoding(+4重载)方法直接获取指定的字符集编码对象。例如,下面的代码:
//获取指定的编码描述信息 Encoding gb18030Encoding = Encoding.GetEncoding("GB18030"); Encoding asciiEncoding = Encoding.ASCII; Console.WriteLine("编码标识符:{0,-10}编码名称:{1,-12}编码说明:{2}", gb18030Encoding.CodePage, gb18030Encoding.HeaderName, gb18030Encoding.EncodingName); Console.WriteLine("编码标识符:{0,-10}编码名称:{1,-12}编码说明:{2}", asciiEncoding.CodePage, asciiEncoding.HeaderName, asciiEncoding.EncodingName); 运行如下:

2.3在不同编码之间进行转换
我们可以可以通过利用 Encoding.Convert(+2重载)直接将字节数组从一种编码转换为另一种编码。下面我们同样通过一个示例代码来学习如何对不同编码的字节序列进行转换。下面的示例程序,为了清楚的演示如何使用,可能代码比较冗余(代码中包含解码和编码部分,在随后会给出相应示例),实际的应用中我们可以根据自己的情况进行适当的对方法抽象,重构,提升程序的可读性和效率。代码如下:
using System;using System.Collections.Generic;using System.Linq;using System.Text;namespace ConsoleApplication1{ class Program { public static void Main() { //不同编码之间的转换 string GB18030String = "你好!晴天猪"; Console.WriteLine("需要转换的字符串:{0}",GB18030String); #region 对字符进行GB18030格式编码 //获取编码器 Encoding gb18030Encoding = Encoding.GetEncoding("GB18030"); //将字符串转换为char类型数组 char[] chars = GB18030String.ToCharArray(); //获取编码为字节序列后的字节数组长度 int buffLength = gb18030Encoding.GetByteCount(chars, 0, chars.Length); //根据获取的字节长度声明数组,存储编码后的字节 byte[] gb18030Buffer = new byte[buffLength]; //获取GB18030编码的字节序列 gb18030Buffer = gb18030Encoding.GetBytes(chars, 0, chars.Length); Console.WriteLine("GB18030编码的字节序列:{0}", BitConverter.ToString(gb18030Buffer)); //将GB18030编码的字节序列转换成UTF-8编码的字节序列 byte[] unicodeBuffer = Encoding.Convert(gb18030Encoding, Encoding.UTF8, gb18030Buffer); Console.WriteLine("转换为UTF-8编码字节序列:{0}", BitConverter.ToString(unicodeBuffer)); #endregion #region 将GB18030编码转换为UTF-8编码 //获取UTF-8解码 Decoder utf8Decoder = Encoding.UTF8.GetDecoder(); //获取解码为字符后字符数组的长度 int utfChartsLength = utf8Decoder.GetCharCount(unicodeBuffer, 0, unicodeBuffer.Length, true); //根据获取解码后的长度创建char数组 char[] utfChart = new char[utfChartsLength]; //将UTF-8编码的字节序列转换为字符数组 utf8Decoder.GetChars(unicodeBuffer, 0, unicodeBuffer.Length, utfChart, 0); StringBuilder strBuilder = new StringBuilder(); foreach (char ca in utfChart) { strBuilder.Append(ca); } Console.WriteLine("UTF-8的字符序列解码:{0}", strBuilder.ToString()); #endregion Console.ReadLine(); } }} 运行程序:

3.C#编码和解码
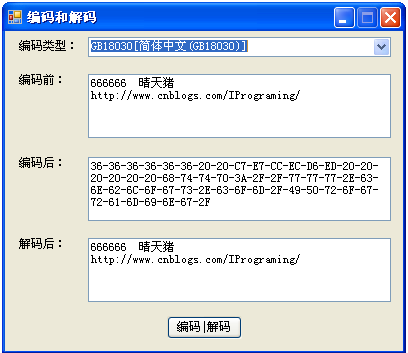
在C#中为我们提供了Encoder和Decoder类,分别对字符进行编码和对字节序列进行解码的两个类。通过使用它们,我们可以很方便进行对字符和字节序列进行编码和解码操作。由于它们的构造函数都是protected级别的,需要使用 Encoding 实现的GetEncoding方法才能获取到它们的实例对象。下面我们通过一个Windows Forms示例程序来了解和学习如何使用这两个类,编码和解码的主要代码如下:
View Code ////// 获取字符串编码之后的bytes数组 /// /// 编码类型名称 /// 将被编码的字符串 ///private byte[] GetEncodeBeforeBuffer(string codeType,string strCode) { //根据编码类型构造该类型编码的编码器的实例 Encoder encoder = Encoding.GetEncoding(codeType).GetEncoder(); char[] chars = strCode.ToCharArray(); //根据获取对字符进行编码所产生的字节数来创建一个byte数组 byte[] bytes = new byte[encoder.GetByteCount(chars, 0, chars.Length, true)]; //将字符写入到byte数组中 encoder.GetBytes(chars, 0, chars.Length, bytes, 0, true); return bytes; } /// ///获取字符串解码之后的字符串 /// /// 编码格式 /// 编码的字节数组 ///private string GetDecodeBeforeText(string codeType, byte[] byteCode) { //根据编码类型构造该类型编码的解码器的实例 Decoder decoder = Encoding.GetEncoding(codeType).GetDecoder(); //计算对字节序列(从指定字节数组开始)进行解码所产生的字符数 char[] chars = new char[decoder.GetCharCount(byteCode, 0, byteCode.Length,true)]; //根据获取的解码所产生的字节数来创建一个char数组 int charLen = decoder.GetChars(byteCode, 0, byteCode.Length, chars, 0); StringBuilder strResult = new StringBuilder(); foreach (char c in chars) { strResult = strResult.Append(c.ToString()); } return strResult.ToString(); }
运行程序:
猛点击下载: